
[Data Science] Evaluation - Sklearn
Evaluation - Sklearn
예측모델을 만들고 예측을 하였다면 모델이 얼마나 정확도를 가지는지 평가를 해야합니다. 그렇다면 어떻게 모델을 평가를 해야할까요 ? 성능을 평가하는 방법은 Metric이라고 하며 크게 3가지가 있습니다.
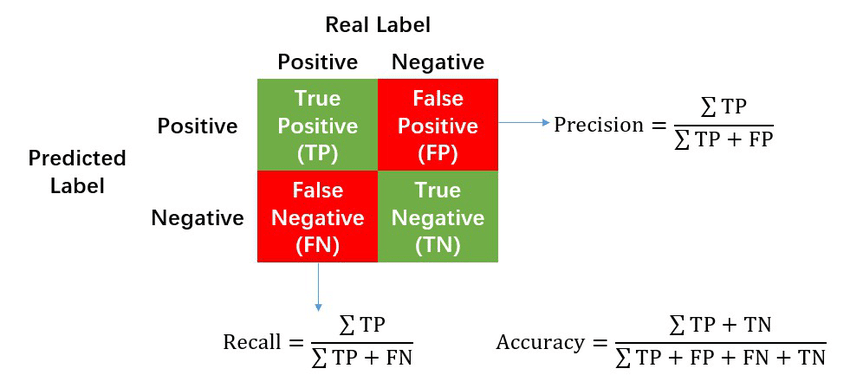
Precision : 맞다고 예측한 것과 실제로 맞은값의 비율
Recall : 실제로 True인 것과 실제 True와 모델이 True라과 예측한 것의 비율
Accuracy : 실제로 맞은 비율
최종모델의 Accuracy를 측정하기 위한 Data Set은 Training set, Validation set, Test set 이 있습니다.
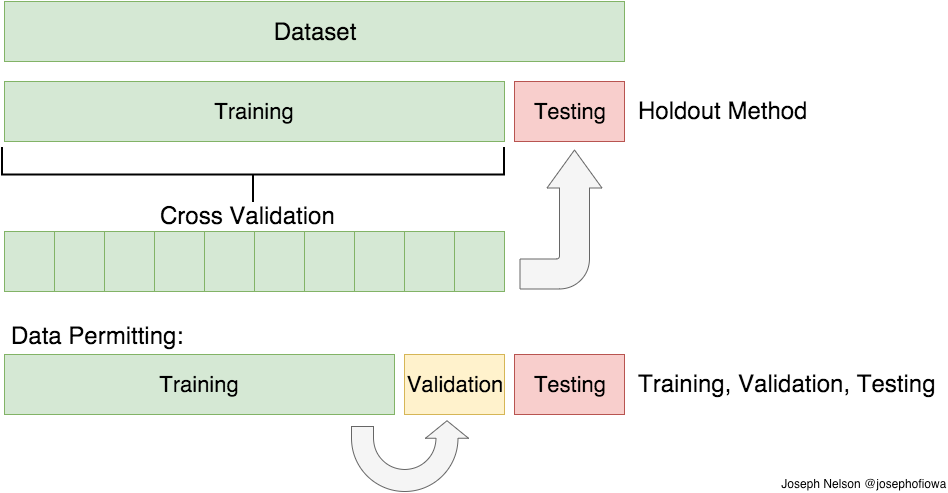
여기서 모델을 학습시키는데 관여하는 데 사용되는 Data set은 Training set 입니다. 중간에 조금 생소한 개념이 있습니다. 바로 Validation set 입니다. 그냥 Training set을 이용하여 학습하고 Test set으로 평가를 하면되는데 왜 Validation 이라는 개념을 만들었을까요?
그 이유는 Training Set으로 학습했을때 발생하는 Overfittinig 과 underfitting 을 막기 위함에 있습니다. Model의 개선작업을 수행하는 역할을 하며 최종적인 평가 중에 예측모델을 조금씩 확인하는 개념으로 보시면 되겠습니다.
하지만 데이터량이 너무 적은 경우에는 Cross validation 을 통해 Training Data를 나누고 Training 과 Test 를 반복합니다.
그렇다면 Sklearn 을 통해서 실습을 해보도록 하겠습니다.
import numpy as np
import pandas as pd
from scipy import stats
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score
from sklearn.metrics import precision_score, recall_score, accuracy_score
#1. Raw Data Loading
df = pd.read_csv('./data/bmi.csv', skiprows=3)
#2. 결측치 확인
print(df.isnull().sum())
#3. 이상치 확인
zscore_threshold = 1.8
for col in df.columns:
outlier = df[col][np.abs(stats.zscore(df[col])) > zscore_threshold]
df = df.loc[~df[col].isin(outlier)]
#4. Data Split
from sklearn.model_selection import train_test_split
x_data_train, x_data_test, t_data_train, t_data_test =\
train_test_split(df[['height','weight']],
df['label'],
test_size=0.3,
random_state=0) # test data를 30% 로 설정
#5. Normalization (정규화)
x_scale = MinMaxScaler()
x_scale.fit(x_data_train)
x_data_train_norm = x_scale.transform(x_data_train)
x_data_train_norm = x_scale.transform(x_data_test)
#6. Sklearn으로 구현
model = LogisticRegression()
model.fit(x_data_train_norm, t_data_train)
#7. Cross Validation
Kfold = 10
Kfold_score = cross_val_score(model, x_data_train_norm, t_data_train, cv=Kfold)
print('##########cross validation############')
print('score : {}'.format(kfold_score))
'''
score : [0.98 0.98642857 0.985 0.97642857 0.98642857 0.98428571
0.98714286 0.97714286 0.97714286 0.98642857]
'''
print('전체평균은 : {}'.format(kfold_score.mean()))
# 전체평균은 : 0.9826428571428572
#8. 최종모델 평가
predict_val = model.predict(x_data_train_norm)
acc = accuracy_score(predict_val, t_data_test)
print('우리 model의 최종 Accuracy : {}'.format(acc))
#9. predict
height = 188
weight = 78
my_state = [[height, weight]]
my_state_val = model.predict(scaler.transform(my_state))
print(my_state_val)

Leave a comment